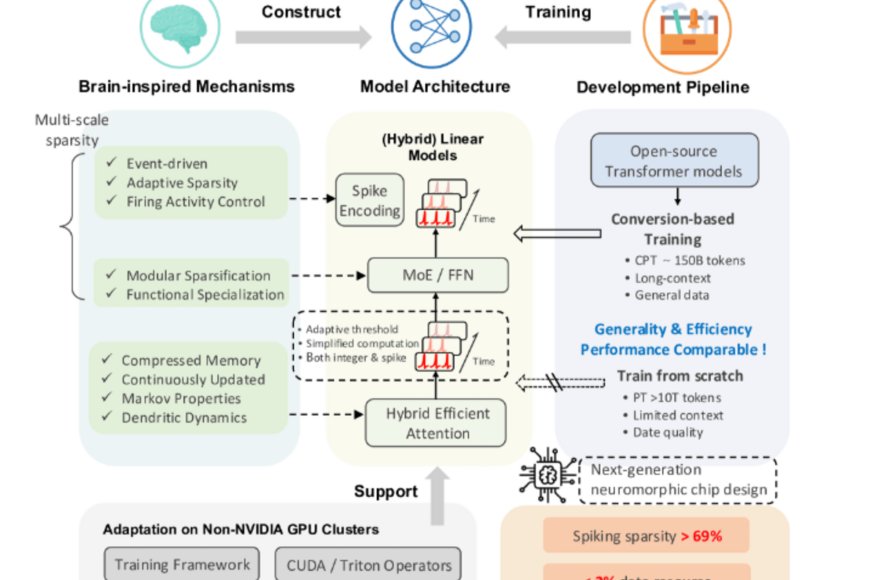
Pechino presenta SpikingBrain, una famiglia di LLM bio-ispirati che promette significativi risparmi energetici e un importante vantaggio nelle sequenze molto lunghe. Secondo quanto affermano i ricercatori, nel technical report e nel repository del progetto, il nuovo modello, che fonde i meccanismi che imitano il cervello con efficenti architetture per il linguaggio naturale, raggiungerebbe un’accelerazione fino a 100 volte sul tempo di generazione del primo token per sequenze estremamente lunghe e una riduzione del consumo energetico dell’97,7% rispetto ad operazioni FP16 stimate. SpikingBrain, che è addestrato su hardware nazionale MetaX con una quantità di dati di pre-training più contenute rispetto ai grandi concorrenti, nasce dall’adozione delle Spiking Neural Networks, le reti che imitano il comportamento dei neuroni biologici. Ciascun neurone accumula segnali e “spara” , ovvero genera uno spike, solo al superamento di una soglia. Questo comportamento genera una sparsità di attivazione, molti neuroni restano inattivi quando non necessari, riducendo così calcoli e accessi memoria. In pratica, mentre un Transformer attiva massicciamente tutte le unità per ogni passaggio, in una SNN l’elaborazione è event-driven e localizzata, il che produce evidenti vantaggi per contesti molto lunghi. Il paper tecnico spiega inoltre come SpikingBrain integri meccanismi di attenzione ibridi e una codifica a spike che rende possibile il calcolo addizionale anziché moltiplicativo,un elemento chiave per l’efficienza energetica e di latenza.
Cosa promette SpikingBrain
La corsa ai LLM ha evidenziato limiti pratici come i costi energetici elevati, la complessità quadratica con la lunghezza della sequenza e la forte dipendenza dall’ecosistema hardware dominato da Nvidia. A questi vincoli SpikingBrain risponde puntando su architetture quasi lineari per l’attenzione, spiking a livello neuronale e ottimizzazioni software-sistema per GPU alternative. Il progetto si inserisce in un contesto più ampio in cui aziende cinesi sviluppano GPU proprie (MetaX è tra queste) per ridurre la dipendenza da fornitori esteri.
I vantaggi pratici riguardano la gestione efficiente di contesti lunghissimi (fino a milioni di token), l'inferenza a basso consumo e i tempi di risposta stabili al crescere dell’input. Le metriche dichiarate includono >100× speedup sul Time to First Token per input da 4 milioni di token e un risparmio energetico stimato del 97,7% rispetto a MAC FP16, basato su stime di energy per operazione e sulla sparsità osservata nelle simulazioni. Sul fronte dati, SpikingBrain-7B è stato addestrato con circa 150 miliardi di token,una quantità di molto inferiore rispetto ad altri modelli che usano trilioni di token, ma raggiungendo comunque performance competitive su benchmark selezionati. Questi risultati implicano potenziali riduzioni di costo e impronta ambientale per applicazioni long-context. E tuttaviai limiti e rischi non vanno sottovalutati. L’adozione pratica richiede verifiche indipendenti sulla riproducibilità, sulla qualità linguistica sui domini diversi e sulla robustezza rispetto a bias e attacchi. L’efficienza misurata su hardware MetaX potrebbe non tradursi identicamente su altre architetture senza adeguati adattamenti software.
SpikingBrain si presenta come una nuova via per ripensare l’architettura dei LLM verso modelli più sparsi e event-driven. La prospettiva per le aziende è quella di ridurre costi energetici e infrastrutturali per carichi long-context. Secondo i policy maker il tema da monitorare è la dipendenza hardware e la necessità di standard di valutazione energetica e di sostenibilità per i modelli su larga scala. Per quelli che oggi vogliono intraprendere una sperimentazione i consigli pratici riguardano la verifica della compatibilità del proprio stack software con l’ecosistema di conversione descritto nel paper, la pianificazione e valutazione indipendenti di consumo energetico su carichi realie e infine considerare benchmark su domini specifici prima dell’adozione produttiva. Gli autori del report osservano chiaramente che “our scheme reduce energy consumption by 97.7% in comparison to the other existing techniques”, sottolineando il valore combinato della codifica a spike e della quantizzazione nel ridurre il costo per operazione.
Uno sguardo verso il domani
Nei prossimi mesi la comunità scientifica guarderà ai risultati della riproducibilità del modello da parte di gruppi indipendenti, alla maturity dell’ecosistema software per eseguire conversioni e inference su diverse GPU e all’adozione di metriche standard per misurare effettiva efficienza energetica in scenari reali. Se confermati, SpikingBrain e approcci SNN-based potrebbero estendere la finestra d’uso pratico dell’IA su testi molto lunghi e dispositivi con vincoli energetici.
Fonti e risorse
SpikingBrain — Spiking Brain-inspired Large Models (technical report, arXiv). (arxiv.org)
BICLab — repository SpikingBrain-7B su GitHub (codice e pesi). (github.com)
MetaX — sito ufficiale (informazioni su GPU MetaX e prodotti). (metax-tech.com)
Reuters — contesto sulle GPU cinesi e indipendenza hardware. (reuters.com)