L’intelligenza artificiale generale, quella capace di affrontare qualsiasi problema con flessibilità, adattamento e consapevolezza, è spesso evocata come il traguardo ultimo della ricerca sul machine learning. È la promessa implicita dietro ogni aggiornamento dei modelli più avanzati, l’obiettivo di fondo che distingue un assistente statistico da una mente sintetica. Ma a che punto siamo realmente?
Un recente studio condotto da un team di ricercatori Apple e pubblicato con il titolo “The Illusion of Thinking” getta nuova luce sulla questione. I modelli presi in esame non sono i classici LLM, ma quelli più evoluti e dichiaratamente progettati per “ragionare”, i cosiddetti Large Reasoning Models. Alcuni dei nomi coinvolti sono noti: Claude 3.7 in versione "Thinking", DeepSeek-R1, OpenAI o3. Si tratta di sistemi che, prima di rispondere, simulano un processo di riflessione interna, costruendo una catena di pensieri, spesso anche con passaggi di autocorrezione.
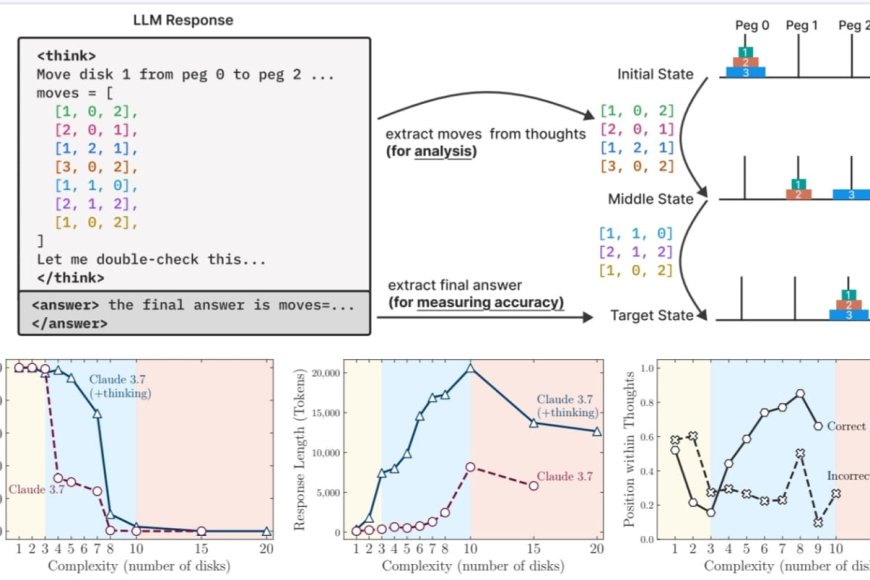
L’originalità dello studio sta nell’avere evitato i classici benchmark matematici, troppo esposti al rischio di contaminazione dei dati. I ricercatori hanno preferito ambienti controllati, una serie di puzzle logici come la Torre di Hanoi, i salti delle pedine, gli attraversamenti fluviali e la riorganizzazione di blocchi. Ogni puzzle è stato reso progressivamente più complesso, mantenendo però regole precise e strutture valutabili in modo deterministico. Così facendo, non si è valutata solo la correttezza della risposta finale, ma anche la qualità e l’efficienza del percorso logico.
I risultati sono netti e controintuitivi. I modelli che “pensano” non sono sempre migliori di quelli che non lo fanno. Anzi, in molti casi, i modelli “non-thinking” hanno fornito risposte più accurate, usando meno risorse. Solo in una fascia intermedia di difficoltà, i modelli reasoning hanno mostrato un vantaggio. Ma al crescere della complessità, entrambi i tipi di modelli sono collassati: errori totali, risposte senza senso, perdita completa della coerenza logica. Una vera e propria frattura cognitiva. Colpisce soprattutto che, in prossimità di questa soglia, i modelli reasoning comincino a “pensare meno”, cioè a ridurre il numero di token dedicati alla riflessione, pur avendo ancora spazio a disposizione. È come se la fatica cognitiva li spingesse a mollare.
Qui il termine token va inteso non come contenuto, ma come unità di computazione. I modelli ragionano scrivendo e leggendo sé stessi. Più pensano, più token consumano. Ma dopo un certo punto, iniziano a scorciare la riflessione, non per efficienza, ma per incapacità. Questo comportamento è un indizio forte: la generazione del pensiero non segue una logica intenzionale, ma resta vincolata da dinamiche statistiche interne e da limiti di architettura.
Interessante anche il tema dell’autoverifica. I modelli reasoning dovrebbero analizzare i propri ragionamenti e correggersi. Nella pratica, succede poco. A volte trovano la risposta giusta subito, ma continuano a ragionare e finiscono per invalidarla. In altri casi, si fissano su una strada sbagliata e la portano avanti fino all’errore finale. In nessun caso si osserva un vero comportamento metacognitivo. È una simulazione di pensiero, non un pensiero autentico.
L’impressione che resta, alla fine, è quella suggerita dal titolo stesso dello studio: l’illusione del pensiero. Questi modelli imitano le forme del ragionamento, ma non ne padroneggiano la sostanza. Non costruiscono strategie generalizzabili, non trasferiscono l’esperienza da un contesto all’altro, non comprendono davvero. L’intelligenza generale, quella che attraversa domini e si adatta a situazioni nuove, non è ancora all’orizzonte. Forse è più lontana oggi di quanto si voglia ammettere.